Конкурентное пересоздание индексов в postgresql
На таблице postgresql с большим количеством данных невозможно быстро создать либо пересоздать индекс. При создании индекса таблица блокируется для операций INSERT, UPDATE и DELETE. В таких случаях может помочь конкурентное создание индекса. Иногда на postgresql стоит пересоздавать индексы, чтобы уменьшить их фрагментацию (и увеличить скорость). Создание конкурентного индекса будет частным случаем его пересоздания.
Пусть имеется таблица orders с 1 миллионом записей (приблизительно) в которой хранятся заказы. И в этой таблице есть поля country_id, region_id, city_id, на которых создан индекс.
Использование очередей в высоконагруженных проектах
При большом количестве запросов к приложению (в широком смысле этого слова) иногда целесообразно ``размазать’’ пиковую нагрузку во времени. Для этого удобно использовать очереди. То есть, если какое-то запрос наверняка должен быть выполнен, но не имеет значение произойдет это прямо сейчас или чуть попозже, можно создать событие в очереди. И когда до этого события дойдет очередь —– оно будет выполнено. Таким образом можно развести сложные запросы во времени.
Очереди подходят для таких задач, как, например, рассылка большого количества сообщений и обновление различных счетчиков в БД (если их актуальность не очень критична). Использование такого подхода позволяет контролировать пиковую нагрузку, за счет чего сделать систему более стабильной в работе и отказоустойчивой. Также это позволяет оставить приемлемое время ответа сервиса, потому что он сможет отвечать что-то до фактического завершения длинной операции.
Отмена последнего коммита в git
Допустим, вы сделали commit в git, но поняли, что он недостаточно хорош. В таком случае можно продолжить правки, а при следующем коммите набрать
git commit -a --amend
Ключ --amend (улучшить, в переводе с английского) позволяет добавить к последнему коммиту новые изменения.
Если вы сделали commit в git, но поняли, что он достаточно плох, то можно сделать и так:
git reset --soft HEAD^
Эта команда отменит последний коммит (но не изменения, которые вы внесли, они сохранятся).
Тесты и тестирование
Возможно, в сайте из 3 контроллеров и 15 страниц, тесты и не нужны. Я обычно не делаю тесты на маленьких проектах, которые пишу один.
В случае, если проект собирается быть большим, длиться долго, а команда состоит больше чем из одного человека, то тесты — крайне желательный инструмент для того, чтобы разработка не вышла из под контроля. Без тестов в какой-то момент невозможно внести серьезное изменение в код, потому что знаешь, что такое изменение заденет еще некоторые части и точно знаешь, что все зависимости точно не учтешь. В этот момент разработка превращается в постоянное исправление ошибок, при которых снова вносятся ошибки и так до бесконечности.
Проблемы с кэшированием
Все ситуации, о которых я здесь пишу, встретились мне в повседневной работе. Единственное, что я делаю — меняю название классов, чтобы не утруждать моего читателя незнакомой для него предметной областью.
Итак, у нас есть следующие модели:
# shop.rb
class Shop < ActiveRecord::Base
has_many :categories
cached_methods do
def wait_orders_count
Order.count :conditions => {:status_id => Order::WAIT}
end
def paid_orders_count
Order.count :conditions => {:status_id => Order::PAID}
end
def bad_orders_count
Order.count :conditions => {:status_id => Order::BAD}
end
end
end
class Category < ActiveRecord::Base
belongs_to :shop
has_many :products
end
class Product < ActiveRecord::Base
belongs_to :category
has_many :orders
end
class Order
belongs_to :product
end
Методы внутри cached_methods выполняются в том случае, если значение для них не нашлось в кэше (например, в memcached).
До этого поля *_orders_count хранились в базе и мы добавляли к ним +1/-1 каждый раз, когда изменяли статус заказа
(Order). Если магазин большой, то таких обновлений будет очень много, что создает нагрузку на базу, поэтому их и вынесли
в кэш. Чтобы не думать, каждый раз при обновлении статуса заказа, мы полностью сбрасывали кэши для конкретного магазина.
PosgtreSql, миграции и огромные таблицы
Миграции в rails — это очень правильный инструмент. Правда, иногда случаются казусы, потому что конкретная БД перестает быть «сферическим конем в вакууме», как только количество данных и нагрузка на нее становится существенной.
Пусть у нас есть таблица posts, в которой 10 миллионов записей. И мы решили добавить в нее поле is_searchable.
$ script/generate migration add_is_searchable_to_posts
class AddIsSearchableToPosts < ActiveRecord::Migration
def self.up
add_column :posts, :is_searchable, :boolean, :default => true, :null => false
end
def self.down
remove_column :posts, :is_searchable
end
end
Если на базе development данных у вас немного, то миграция пройдет замечательно. На production базе она может занять несколько часов, блокируя таблицу posts. Заглянув в документацию по postgresql и немного подумав, можно переписать эту миграцию вот так:
Перенести ветку в git
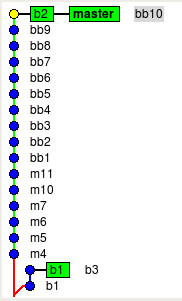
Представим следующую ситуацию (она постоянно возникает у нас при разработке). У нас есть ветка master в git, а в день релиза мы создаем ветку b1. Мы добавляем какие-то изменения в ветки b1 и master. И тут вдруг (хотя слово «вдруг» не очень подходит к регулярным событям) менеджмент решает добавить что-то из master в релиз.
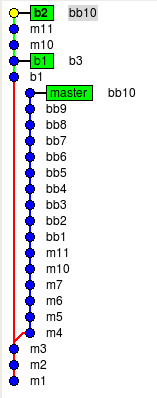
Если комитов было мало, то
можно воспользоваться git cherry-pick (если их несколько, то может помочь ключ -n). А что делать, если комитов было
больше 10? Рукаме делать git cherry-pick не очень удобно. В таком случае нам поможет (в который раз) git rebase.
Непрерывная интеграция
О непрерывной интеграции (Continuous Integration) можно почитать у Мартина Фаулера (Martin Fowler) здесь. В друх словах, это практика постоянной интеграции наработок каждого программиста. Обычно это заключается в том, что на какой-нибудь машине постоянно (после каждого изменения в исходных кодах) собирается проект и прогоняются все тесты. Результаты этих действий высылаются разработчикам по почте. Это позволяет постоянно сохранять проект в относительно рабочем состоянии.
Удобным инструментом непрерывной интеграции является CruiseControl. К сожалению в своей оригинальной версии он поддерживает только систему контроля версий svn. Поддержку git дописали народные умельцы. Я воспользовался вот этой веткой.
Использование capistrano
Для выкатки (deploy) я не знаю другого инструмента, кроме capistrano. Слышал про vlad, но в глаза его никогда не видел.
Использовать capistrano имеет смысл при любом размере проекта, будь то сайт из 3-5 страничек, или что-то большое. Во втором случае отказ от использования capistrano — форменное безумие с моей точки зрения.
Начать знакомиться лучше всего отсюда.
Если вкратце, то заходим в каталог проекта и набираем:
capify .
Дальше правим файл config/deploy.rb, в нем все более или менее понятно.