БД — большой кэш
В прошлый раз я обещал написать о том, что в проектах с более менее серьезной нагрузкой БД либо помещается в память, либо не работает. Ситуация в современном мире меняется в связи с появлением SSD дисков, но пока что они стоят достаточно дорого, по сравнению со старыми добрыми вращающимися дисками. Чтобы «потрогать» это руками, проделаем несложный тест.
Я завел новую машину с Ubuntu 12.04, на облачном хостинге Amazon размера t1.micro. После этого необходимо поставить 2 пакета: postgresql-contrib-9.1 и ruby.
PostgreSQL contrib содержит, помимо всего прочего, программу pgbench, специально предназначенную для нагрузочного тестирования PostgreSQL.
В postgresql.conf параметр shared_buffers был выставлен в 64MB.
Далее был написан скрипт на ruby, который проводил тестирование:
File.open('res.txt', 'w') do |f|
(1..50).each do |s|
# -i означает, что мы создаем чистую БД
# -s - это scale factor, определяет размер БД
`/usr/lib/postgresql/9.1/bin/pgbench -i -s #{s}`
# -S - тесты для запросов только на чтение
# -T 20 - тест длится 20 секунд
# -c 40 - 40 клиентов
# -j 4 - 4 потока
res = `/usr/lib/postgresql/9.1/bin/pgbench -c 40 -j 4 -S -T 20`
puts res
f.write res
end
end
Более подробно про pgbench можно почитать в официальной документации.
На машинках t1.micro free -m выдает следующее:
total used free shared buffers cached
Mem: 590 583 6 0 1 428
Именно этим обусловлен такой выбор границ scale factor. Про scale factor = 50 размер БД приблизительно 750Мб, то есть больше количества доступной памяти, а граница shared_buffers пересекается при значениях scale factor 4-5.
Давайте же посмотрим на график.
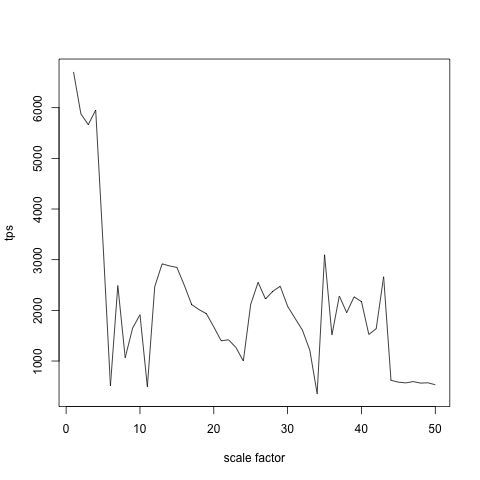
Данные получились не очень красивыми, но в целом — понятными. Виден провал в районе scale factor 5, а следующий провал в районе scale factor 45. Собственно, две явные ступеньки — выпадание из shared buffers и из дискового кэша.
Параметр shared_buffers отвечает за то, сколько памяти будет использовано PostgreSQL для общего кэша, доступного всем процессам БД. Если какие-то данные попадают в shared buffers, то доступ к ним осуществляется быстрее всего. Более того, все изменения shared buffers происходят с правильными блокировками, поэтому данные там всегда актуальны. По большому счету именно этот большой кэш позволяет БД быстро работать. Более того, в PostgreSQL используется специальный алгоритм, который помогает наиболее часто используемым данным попадать и оставаться в этом кэше.
Следующий уровень — это дисковый кэш операционной системы. Вся свободная память ОС linux используется как дисковый кэш. Конечно, доступ к данным, которые лежат в дисковом кэше будет осуществляться медленнее, чем к тем, что лежат в shared buffers. Но все же это будет происходить достаточно быстро.
Если же данные не были обнаружены в дисковом кэше, то ОС полезет за ними на диск. И это очень-очень долго (конечно, не ясно, что за диски внутри Amazon, но это точно не SSD). Обычный диск может выдать 100-200 случайных операций в секунду (посмотрите калькулятор IOPS), и если количество запросов значительно превышает возможности дисковой подсистемы, то такой режим работы БД обычно называют «у нас легла БД».
Диски являются самым дорогим ресурсом для БД, поэтому их надо экономить и тратить их ресурсы в основном только на запись. Все актуальные данные должны попадать в кэш БД или кэш ОС. Именно поэтому всегда рекомендуют держать для отчетов отдельный сервер БД. Обычно данные, которые нужны для отчетов, не используются на web-сайте. И как только запускается аналитический отчет, он вымывает данные из кэша ОС и БД, и сайт буквально ложится, что мы наблюдали неоднократно у наших клиентов. Конечно, такое происходит только в том случае, если размер БД значительно превышает размер оперативной памяти на сервере.
PS Для любителей PostgreSQL хорошо известный в Ruby-мире Питер Купер выпускает рассылку PostgreSQL Weekly.